
Concurrency is Hard.
I’d say it’s definitely somewhere at the top of the list among things that can cause a headache to a software engineer and create many joyful hours of debugging while trying to understand a strange bug. The type that seems to happen randomly, usually to someone on production, but eludes you when you try to reproduce it.
All of a sudden, you figure out how to replicate it. You reproduce it five times in a row, confident that you finally got it. But just to be sure, you do another round of testing – and it’s not there anymore, even though you didn’t change anything, leaving you totally confused. I hope you were lucky (or smart) and never have encountered this type of problem. But we who did, at least in the C++ world, call this undefined behavior. One of the common reasons it occurs is a race condition in multithreaded applications.
A Glimpse Into the Past.
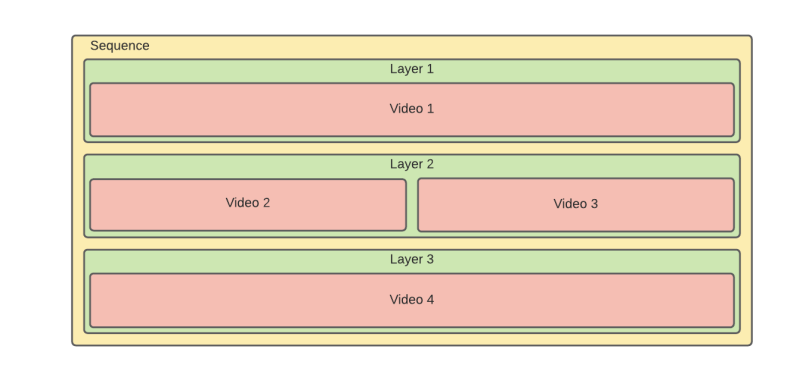
Some time ago, I was part of the team developing an application that is, in essence, a video mixer. It could play videos sequentially and in parallel, and any combination of the two. We called that combination of multiple visuals a Sequence. A sample Sequence could look like this:

Every row (called a Layer) could consist of one Video or several Videos playing in Sequence, one after another.
The Sequence was the combination of Layers playing in parallel. In the example above, at first, Video 1, Video 2, and Video 4 would play in parallel, and in the second half of the Sequence, Video 1, Video 3, and Video 4.
We used a Composite pattern to model this:

Different implementations share some similar properties, but they’re calculated differently.
For instance, the above-mentioned GetDuration function for Video would simply return the duration of Video in milliseconds.
Layer duration would be a sum of all Videos since they play sequentially, and the duration of a Sequence would be the duration of its longest Layer.
Our sample Sequence would be composed of the following objects:
To actually play this model, we created another set of classes, again using a Composite pattern:
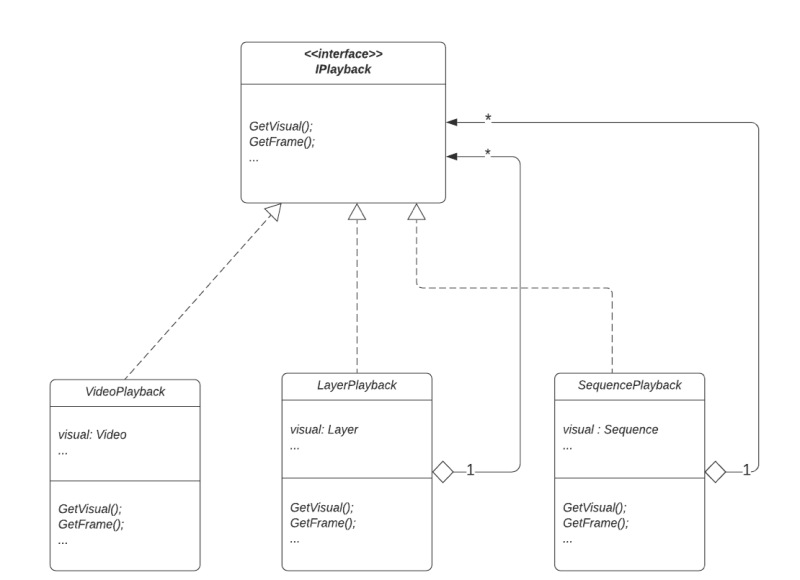
Everything implements interface IPlayback, but common functions are different according to the implementing class.
The most important function—GetFrame—actually produces a bitmap of the frame. In the case of Video, it just returns a Video frame from the loaded video file.
In the case of LayerPlayback, GetFrame will provide a bitmap depending on the position in the Sequence. In our example, Layer 2, in the first half of the Sequence, will return the frame of Video 2, and in the second half, it’ll return the frame of Video 3.
GetFrame of SequencePlayback returns a frame that is a mix of frames from all its Layers using one of the mixing algorithms – we’ll not go into the details of mixing here, but let’s just say it produces exciting results.
Once we create this structure, objects look like this:

Basically, playback objects have pointers to model objects they use and read some properties needed to produce a frame.
In case you’re wondering why we had a separate structure for playback objects, here’s a short explanation:
Playback structure is stateful in nature.
Most importantly, the position inside a Sequence while playing is part of the playback state. And (without going into too many details) Video, Layer, and Sequence aren’t the only model classes we had. We could also play two Sequences simultaneously, including the same Sequence twice (and they could be started at different times, so producing frames at different time points). In that case, we’d have two stateful SequencePlaybacks reading from the same Sequence object.
This (finally) leads us to the multithreading problems we faced.
A Problem.
Producing a frame from a Sequence is potentially a cumbersome processing task. We allowed up to 8 Layers in one Sequence, so potentially we can have GetFrame called frame from 8 Videos and then mix the results. We could also play 2 Sequences like that in parallel. Because of that, every SequencePlayback was processed by separate threads we called engine threads. And at the same time, Sequence model objects (used by playback objects to get the information needed for producing frames) can be changed by the app user through application GUI. These changes include adding new Videos to Layers, changing their duration, adding some visual effects, removing Videos from Layers, hiding Layer output, changing mixing properties, etc. All that while the Sequence is playing.

We needed to synchronize access to our model objects between the user’s thread (GUI thread) and potentially multiple engine threads.
An Obvious Solution.
The choice we had, of course, was to add mutexes to model objects – as we did. However, this caused several issues.
First of all, as I’ve already mentioned, producing a frame can be a processing-heavy task. The user interface was lagging because it waited on engine threads to free model objects for change. And the other way around, the Video output framerate would sometimes drop if the user was doing changes and locked mutex before engine threads.
Choosing where to put mutex is also a complex task if we put only on per Sequence, lagging was getting worse. If we put one for every object, we’re creating a whole tree of mutexes, and when something goes wrong, it’s tough to debug and figure out what happened.
More importantly, one particular problem was challenging to solve, removing a Video. If the engine thread is using the Video object to read some properties, and the user kicks it out of the Sequence at that point, it produces a dangling pointer – a recipe for undefined behavior.
Whatever we’ve tried, we constantly faced the same problems for a time.
A Solution That Actually Worked.
Fortunately, we had a very experienced colleague on the client-side to consult with our issues. And he gave a straightforward solution: let every thread have its own copy of the model object instead of sharing.
(By the way, I contacted him before writing this blog and asked if there was a name to this pattern. His first answer was: “Hmm.” And after a slight pause, he said: “Only shared data can result in data races.” Very true.)
We redesigned our system to look like this:

All the communication between user (GUI) threads and engine threads is now done via the event queue. When the user initiates playing Sequence start (click in the GUI of the app), we create an event where we set a complete copy of the Sequence model as payload.
Engine thread picks up the event and creates a stateful playback objects structure, using model copy as a source, and it starts producing frames.
From that moment on, any change user does on the model produces an event with the payload containing the information about the change.
Event queue design is straightforward – it consists of two FIFO queue collections. The user (GUI) thread feeds change events into one, and the engine thread reads events from the other.
Engine thread operates in 3 steps:
- Switch queue collections
- Use events from the queue collection and handle them, which syncs the model copy
- Produce frame
All problems with data synchronization are solved – since the engine thread deletes the Video object from its model before producing a frame, no more dangling pointers.
And performance-wise, well, just one small synchronization yet needed, and that’s the moment when the engine thread is switching queues. That’s the only place where user and engine threaded clash, so we had to synchronize engine thread switching queues and GUI thread putting events. But it’s only one mutex, and both operations were really simple and fast, so no lagging. It worked like a charm.
The only other thing we needed to do was add a level of indirection – our model objects needed to have IDs to address what we needed to change in our events. Adding synthetic IDs to our classes was really only a minor inconvenience.
Word of Advice.
The story’s moral is that if you ever need to share some data between threads, the first thing you should try is not to do it. Since you already must, always try and find a way to localize synchronization between threads and limit the number of synchronization primitives to a minimum.
A colleague told me once that already two synchronization points are too much to be able to cope with. I’m not sure about the exact number where it becomes too much. Still, for sure, with every new one, your work becomes exponentially more complex. If you get in a situation where you are adding synchronization primitives left, and right into your code, that’s probably a good sign that you’re going in the wrong direction.
Stop and try to think out of the box for a second. There could be a moderate change to your design that can solve many of your problems.
Probably the best thing you can do is to see if you can adjust your problem to match a well-known problem that already has a mature solution, which is exactly what design patterns are meant for (and this advice goes well beyond concurrent programming).
I had a similar setup several times in my career, recognized the problem is familiar and used the same solution described here to great success.
Finally, if you find the topic interesting, check out an excellent book on concurrency for C++ developers: manning.com/books/c-plus-plus-concurrency-in-action. You can find great insight into the memory model and how it works, which can help better understand why race conditions happen and how to avoid them.
Visit the company profile.